
股票与债券的持仓交易记录方式
不同类型交易合约类型交易(Contract Level Trade):我方与对手方达成协议(合约),特别是场外交易,如利率互换、借贷交易、外汇(FX)等,逐笔记录,按Date执行与结束,不留下任何东西。
持仓类型交易(Position Based Trade):债券(Bond)、股票(Equity)
持仓是指在实物交割或者现金交割到期之前,投资者可以根据市场行情和个人意愿,自愿地决定买入或卖出期货合约。而投资者(做多或做空)没有作交割月份和数量相等的逆向操作(卖出或买入),持有期货合约,则称之为“持仓”。在黄金等商品期货操作中,无论是买还是卖,凡是新建头寸都叫建仓。操作者建仓之后手中就持有头寸,这就叫持仓。
持仓交易股票CASE用户下一个股票订单(Order),在Price上可以有不同的策略,比如以每股不超过18块成交、不care每股多少钱等:
券商把订单送到交易所,返回的是一个执行结果(Execution),会有多种cases,比如就以18块买入:
或者是有部分股以更低的价格买入:
这里可以有另一种记录方式,就是记一笔加权成交价:
交易所会当天冻结交易的资金,并且把股票 ...
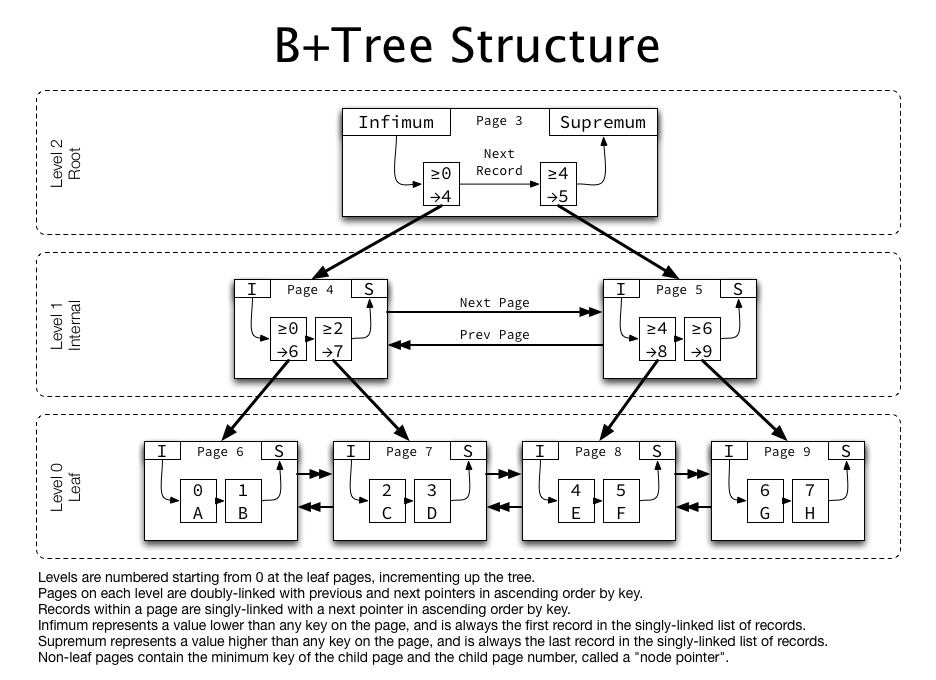
为什么 MySQL InnoDB 存储引擎底层数据结构选用 B+ 树而不是 B 树?
树的演进过程二叉查找树(BST)特点
任意节点左子树不为空,则左子树的值均小于根节点的值;
任意节点右子树不为空,则右子树的值均大于根节点的值;
任意节点的左右子树也分别是二叉查找树;
没有键值相等的节点。
局限解决了排序的基本问题,比普通树查找更快,查找、插入、删除的时间复杂度为O(logN)。但是由于无法保证平衡,可能退化为链表。
平衡二叉树(自平衡二叉查找树,AVL)特点AVL树是带有平衡条件的二叉查找树,一般是用平衡因子差值判断是否平衡并通过旋转来实现平衡,左右子树树高不超过1,和红黑树相比,它是严格的平衡二叉树,平衡条件必须满足(所有节点的左右子树高度差不超过1)。
不管是执行插入还是删除操作,只要不满足上面的条件,就要通过旋转来保持平衡。
局限由于维护这种高度平衡所付出的代价比从中获得的效率收益还大(旋转操作效率太低),故而实际的应用不多,更多的地方是用追求局部而不是非常严格整体平衡的红黑树。当然,如果应用场景中对插入删除不频繁,只是对查找要求较高,那么AVL还是较优于红黑树。
红黑树特点一种二叉查找树,但在每个节点增加一个存储位表示节点的颜色,可以是red或black。 ...
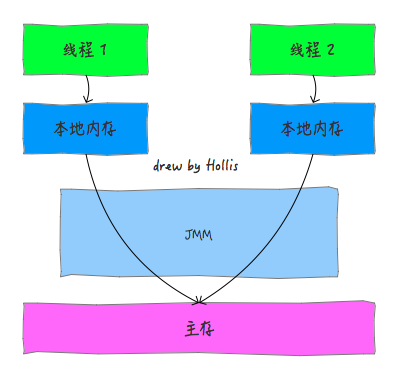
Java内存模型(JMM)
JMM的由来内存模型的由来内存模型,英文名Memory Model,他是一个很老的老古董,是与计算机硬件有关的一个概念。
计算机在执行程序的时候,每条指令都是在CPU中执行的,而执行的时候,又免不了要和数据打交道。而计算机上面的数据,是存放在主存当中的,也就是计算机的物理内存。随着CPU技术的发展,CPU的执行速度越来越快。而由于内存的技术并没有太大的变化,所以从内存中读取和写入数据的过程和CPU的执行速度比起来差距就会越来越大,这就导致CPU每次操作内存都要耗费很多等待时间。
所以,人们想出来了一个好的办法,就是在CPU和内存之间增加高速缓存。缓存就是保存一份数据拷贝,特点是速度快,内存小,并且昂贵。
那么,程序的执行过程就变成了:当程序在运行过程中,会将运算需要的数据从主存复制一份到CPU的高速缓存当中,那么CPU进行计算时就可以直接从它的高速缓存读取数据和向其中写入数据,当运算结束之后,再将高速缓存中的数据刷新到主存当中。
而随着CPU能力的不断提升,一层缓存就慢慢的无法满足要求了,就逐渐的衍生出多级缓存。
按照数据读取顺序和与CPU结合的紧密程度,CPU缓存可以分为一级缓存(L ...
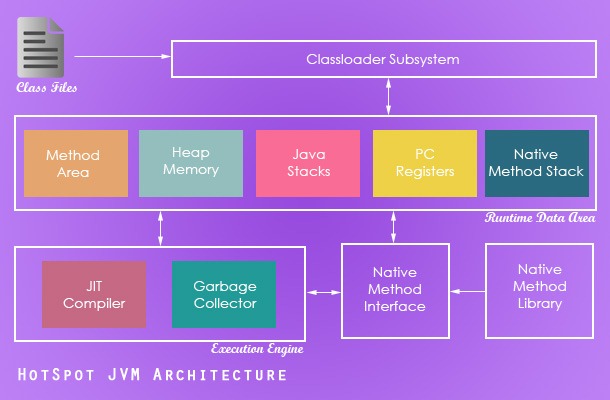
JVM内存结构
内存结构图解通用版Java 虚拟机在运行Java程序时,把它所管理的内存划分为若干个不同的数据区域,主要包括以下五个部分:程序计数器、Java 堆、Java虚拟机栈、方法区和本地方法栈。
Guide哥版JDK 1.6
JDK 1.8
运行时数据区域程序计数器程序计数器是一块较小的内存空间,可以看作是当前线程所执行的字节码的行号指示器,它会指出下一条将要执行的指令的地址。
字节码解释器工作时通过改变这个计数器的值来选取下一条需要执行的字节码指令,分支、循环、跳转、异常处理、线程恢复等功能都需要依赖这个计数器来完成。
程序计数器是线程私有的一小块内存,每条线程都要有一个独立的程序计数器,以使线程切换后恢复到正确的执行位置,所以是线程私有的。
具体数据内容:
如果线程正在执行 Java 方法,则计数器记录的是正在执行的虚拟机字节码指令的地址;
如果执行 native 方法,则计数器为空。
作用:
字节码解释器通过改变程序计数器来依次读取指令,从而实现代码的流程控制,如:顺序执行、选择、循环、异常处理。
在多线程的情况下,程序计数器用于记录当前线程执行的位置,从而当线程被切换回来的时候 ...
分布式事务的解决方案
相关概念事务事务提供一种机制将一个活动涉及的所有操作纳入到一个不可分割的执行单元,组成事务的所有操作只有在所有操作均能正常执行的情况下方能提交,只要其中任一操作执行失败,都将导致整个事务的回滚。简单地说,事务提供一种“要么什么都不做,要么做全套”(All or Nothing)机制。
一致性强一致性任何一次读都能读到某个数据的最近一次写的数据。系统中的所有进程,看到的操作顺序,都和全局时钟下的顺序一致。简言之,在任意时刻,所有节点中的数据是一样的。
弱一致性数据更新后,如果能容忍后续的访问只能访问到部分或者全部访问不到,则是弱一致性。
最终一致性不保证在任意时刻任意节点上的同一份数据都是相同的,但是随着时间的迁移,不同节点上的同一份数据总是在向趋同的方向变化。简单说,就是在一段时间后,节点间的数据会最终达到一致状态。
幂等操作在编程中一个幂等操作的特点是其任意多次执行所产生的影响均与一次执行的影响相同。幂等函数,或幂等方法,是指可以使用相同参数重复执行,并能获得相同结果的函数。这些函数不会影响系统状态,也不用担心重复执行会对系统造成改变。例如,支付流程中第三方支付系统告知系统中某个订单 ...

分布式系统的一致性问题
一致性问题的由来随着分布式系统机器的增多,故障发生的概率也在增加,在一个分布式系统中,硬件或软件都会出现未知的故障或者不正常运行。分布式系统区别于单机系统的一个特性就是它可以容许部分失败,这便是之前分布式系统概念里面提到的容错和故障处理。
故障处理在一个分布式系统中,硬件或软件都会出现未知的故障或者不正常运行,因此故障处理是贯穿整个系统的难题。容错(设计容错机制如重传)、故障恢复(数据恢复或“回滚”保证一致性)、冗余(多条路由或者备份等技术)都是故障处理技术。
分布式系统区别于单机系统的一个特性就是它可以容许部分失败。当分布式一个系统中的一个组件发生故障时就可能产生部分失效,这个故障也许会影响到其它组件的正确操作,但同时也有可能完全不影响其它组件。而在非分布式系统中的故障通常会影响到所有的组件,甚至很容易就使整个系统奔溃。
分布式系统设计的一个重要目标就是:它可以从部分失效中自动恢复,而不会严重的影响整体性能。特别是,当故障发生时,分布式系统应该在进行恢复的同时继续以可接受的方式继续操作,也就是它应该容许错误,在发生错误的时某种程度上仍可以继续操作。
容错容错与被称为“可靠的系统(de ...
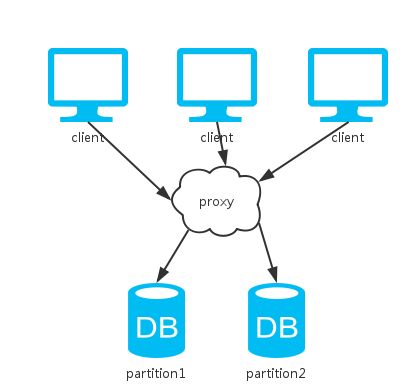
分布式系统简介
什么是分布式系统分布式系统的出现是为了用廉价的、普通的机器完成单个计算机无法完成的计算、存储任务。其目的是利用更多的机器,处理更多的数据。
A distributed system is a collection of independent computers that appears to its users as a single coherent system.分布式系统是若干独立计算机的集合,这计算机对用户来说就像是单个相关系统。
特点:
若干独立计算机
对用户透明
分:把整个系统的功能分割成单一的功能部署到不同的机器不同的服务上。
合:不是简单把分散在各个机器服务上功能再重新放到一台机器上去,而是让这些分散的服务有机组合起来,彼此可以相互协作运行,对外呈现统一的整体。
只有当单个节点的处理能力无法满足日益增长的计算、存储任务的时候,且硬件的提升(加内存、加磁盘、使用更好的CPU)高昂到得不偿失的时候,应用程序也不能进一步优化的时候,我们才需要考虑分布式系统。因为,分布式系统要解决的问题本身就是和单机系统一样的,但是由于分布式系统多节点、通过网络通信的拓扑结构,会引入 ...

缓存与数据库一致性:以Redis为例
常用的3种缓存读写策略Cache Aside Pattern(旁路缓存模式)写 :
先更新 DB;
然后直接删除 cache 。
读 :
从 cache 中读取数据,读取到就直接返回;
cache中读取不到的话,就从 DB 中读取数据返回;
再把数据放到 cache 中。
Read/Write Through Pattern(读写穿透)服务端把 cache 视为主要数据存储,从中读取数据并将数据写入其中。cache 服务负责将此数据读取和写入 DB,从而减轻了应用程序的职责(Redis 里没有提供 cache 将数据写入DB的功能)实际是在 Cache-Aside Pattern 之上进行了封装,让 cache 服务自己来写入缓存,对客户端是透明的。
写(Write Through):
先查 cache,cache 中不存在,直接更新 DB。
cache 中存在,则先更新 cache,然后 cache 服务自己更新 DB(同步更新 cache 和 DB)。
读(Read Through):
从 cache 中读取数据,读取到就直接返回 。
读取不到的话,先从 DB 加载, ...

Redis缓存雪崩、击穿、穿透问题
缓存雪崩定义当大量缓存数据在同一时间过期(失效)或者Redis故障宕机时,如果此时有大量的用户请求,都无法在Redis中处理,于是全部请求都直接访问数据库,从而导致数据库的压力骤增,严重的会造成数据库宕机,从而形成一系列连锁反应,造成整个系统崩溃。
应对大量数据同时过期
避免将大量的数据设置成同一个过期时间,可以给这些数据的过期时间加上一个随机数。
加个互斥锁,保证同一时间内只有一个请求来构建缓存(从数据库读取数据,再将数据更新到 Redis 里);实现互斥锁的时候,最好设置超时时间。
对缓存数据可以使用两个 key,一个是主 key,会设置过期时间,一个是备 key,不会设置过期。key值不一致、value值一致,实质上给缓存数据做一个副本。当访问不到主key时,直接返回备key的缓存数据;更新缓存时同时更新主key和备key的数据。
让缓存“永久有效”,并将更新缓存的工作交由后台线程定时更新。不设置有效期,业务线程不再负责更新缓存。
Redis 故障宕机
启动服务熔断机制,暂停业务应用对缓存服务的访问,直接返回错误,不用再继续访问数据库,等到 Redis 恢复正常后,再允许业务应 ...

离线环境中用pip安装所需要的Python包
Intro实验室服务器限制在内网环境里连接,想要安装一些Python第三方包无法直接通过pip install安装。本次安装背景为两台操作系统与Python版本都近乎一致的机器(如有较大差别可参考不一致时的解决办法),一台可连外网,一台待离线安装。以安装PyHive包需要的库为例。
注:可以在Python交互式终端中用以下两条代码查出当前Python的具体环境信息:
12import pip._internalprint(pip._internal.pep425tags.get_supported())
Onlinepip&Python版本:
12[cuper@iZe4h75o51zvd0Z ~]$ pip -Vpip 21.1 from /usr/local/lib/python3.6/site-packages/pip (python 3.6)
分别安装下列包:
1234pip download saslpip download thriftpip download thrift-saslpip download PyHive
在当前文件夹会发现多出下列文件:
12 ...