《大数据技术原理与应用》学习笔记——Ch4:分布式数据库HBase
Intro
本文为《大数据技术原理与应用》第四章学习笔记。
HBase安装和编程实践指南
HBase简介
HBase是一个高可靠、高性能、面向列、可伸缩的分布式数据库,是BigTable的一个开源实现,主要用来存储非结构化和半结构化的松散数据。

HBase和BigTable的底层技术对应关系:
| BigTable | HBase | |
|---|---|---|
| 文件存储系统 | GFS | HDFS |
| 海量数据处理 | MapReduce | Hadoop MapReduce |
| 协同服务管理 | Chubby | Zookeeper |
在已有Hadoop和HDFS的情况下为什么需要HBase:
- Hadoop无法满足大规模数据实时处理应用的需求
- HDFS面向批量访问模式,不是随机访问模式
- 传统的通用关系型数据库无法应对在数据规模剧增时导致的系统扩展性和性能问题(分库分表也不能很好解决)
- 传统关系数据库在数据结构变化时一般需要停机维护
- 空列浪费存储空间
HBase与传统关系数据库的对比分析
| HBase | 关系型数据库 | |
|---|---|---|
| 数据类型 | 采用了更加简单的数据模型,它把数据存储为未经解释的字符串 | 采用关系模型,具有丰富的数据类型和存储方式 |
| 数据操作 | 不存在复杂的表与表之间的关系,只有简单的插入、查询、删除、清空等 | 包含了丰富的操作,其中会涉及复杂的多表连接 |
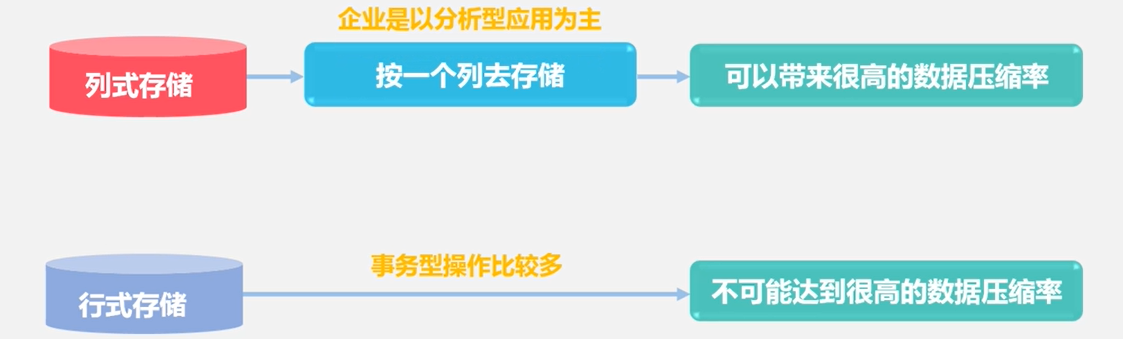
| 存储模式 | 基于列存储的,每个列族都由几个文件保存,不同列族的文件是分离的,可降低I/O开销 | 基于行模式存储的 |
| 数据索引 | 只有一个索引:行键,所有访问均通过行键访问或扫描 | 针对不同列构建复杂的多个索引,以提高数据访问性能 |
| 数据维护 | 执行更新操作时生成一个新的版本,旧有的版本仍然保留 | 更新操作会用最新的当前值去替换记录中原来的旧值,旧值被覆盖后就不会存在 |
| 可伸缩性 | 分布式集群扩展灵活,能够轻易地通过在集群中增加或者减少硬件数量来实现性能的伸缩 | 很难实现横向扩展,纵向扩展的空间也比较有限。 |
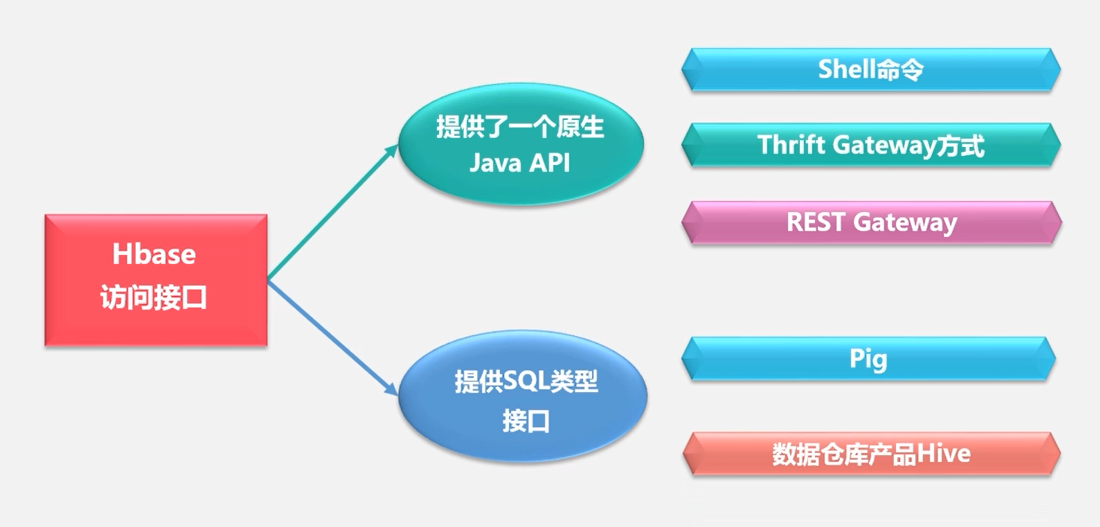
HBase访问接口
HBase数据模型
数据模型概述
- HBase是一个稀疏、多维度、排序的映射表
- 四个索引:行键、列族、列限定符和时间戳
- 每个值是一个未经解释的字符串,没有数据类型
- 每一行都有一个可排序的行键和任意多的列
- 表在水平方向由一个或者多个列族组成,一个列族中可以包含任意多个列,同一 个列族里面的数据存储在一起
- 列族支持动态扩展,可以很轻松地添加一个列族或列,无需预先定义列的数量以及类型,所有列均以字符串形式存储,用户需要自行进行数据类型转换
为什么说HBase是稀疏的:同一张表里的每一行数据都可以有截然不同的列,对于整个映射表来说有些列的值就是空的。
- HBase中执行更新操作时,生成一个新的版本,旧有的版本仍然保留(因为HDFS只允许追加不允许修改)
数据模型相关概念
表
HBase采用表来组织数据,表由行和列组成,列划分为若干个列族
行
每个HBase表都由若干行组成,每个行由行键(row key)来标识
列族
一个HBase表被分组成许多“列族” (Column Family)的集合,它是基本的访问控制单元。
- 不同的列族会存到不同的文件中去
- 需要在表创建时定义好(由于HBase本身的缺陷最多只限于几十个)
- 同一个列族中的数据通常都属于同一种数据类型
- 数据表中每个列都属于某个列族,列名都以列族为前缀:
列族:列名 - 支持权限控制和配置访问模式
列限定符(列)
列族里的数据通过列限定符(列)来定位,动态增减。数据类型始终为byte[]。
单元格
具体存储数据的地方,存储的都是未经解释的字符串。
在HBase表中,通过行、列族和列确定一个“单元格”(cell)。
数据类型始终为
byte[]。每个单元格中可以保存一个数据的多个版本,每个版本对应一个不同的时间戳。
时间戳
每个单元格都保存着同一份数据的多个版本,这些版本采用时间戳进行索引。
每次对单元格进行操作时HBase都会隐式地生成并存储一个时间戳。
一个单元格里不同版本根据时间戳降序存储,最新版本可被最先读取。
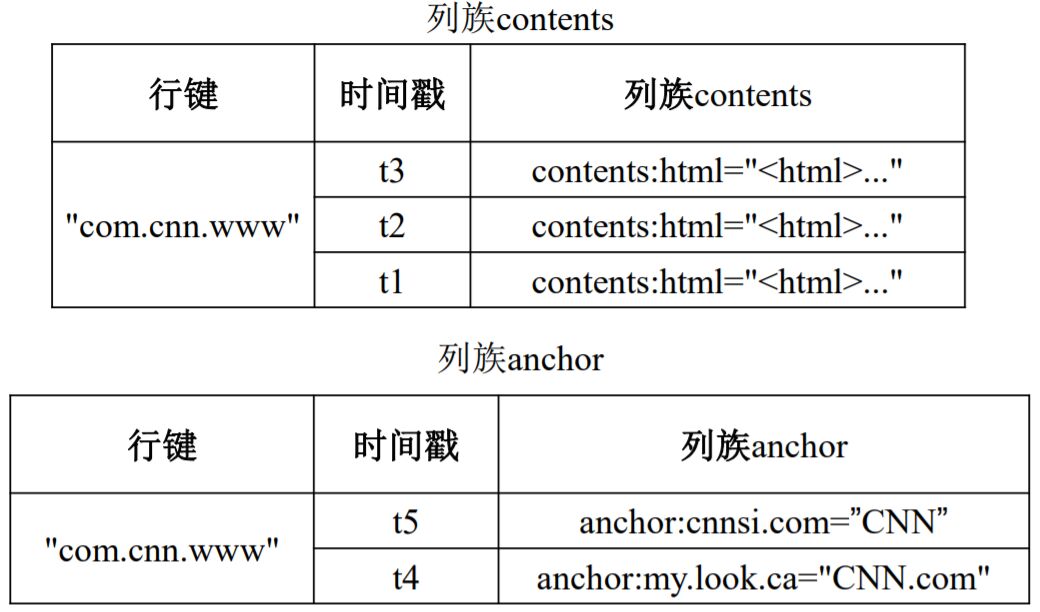
HBase数据模型实例:
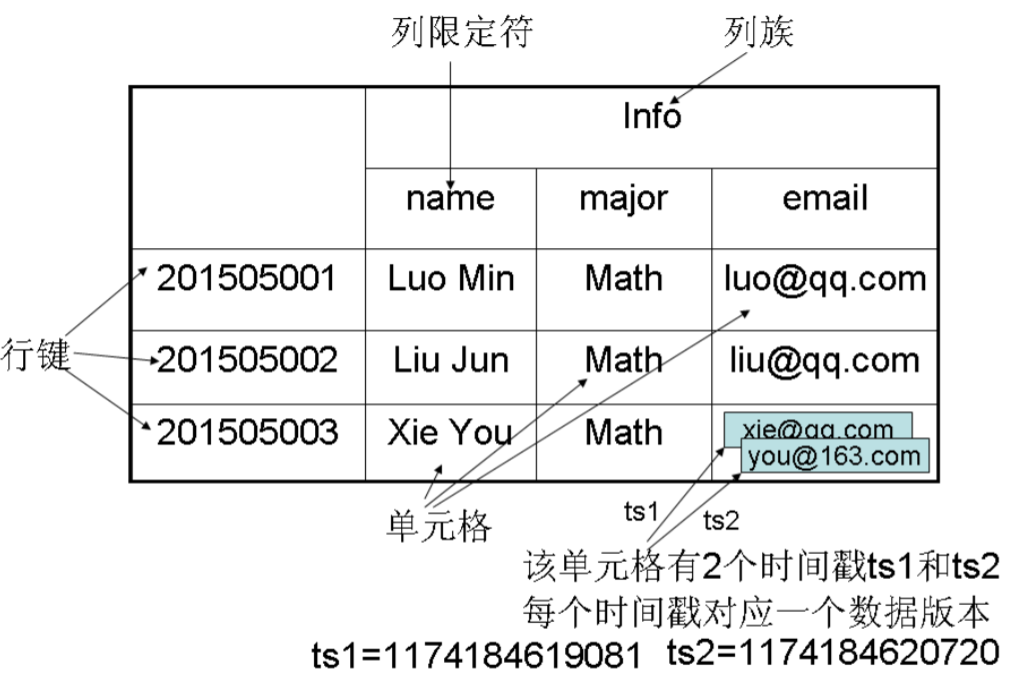
数据坐标
HBase对数据的定位:四维坐标——[行键, 列族, 列限定符, 时间戳]
键值数据库
概念视图与物理视图
概念视图
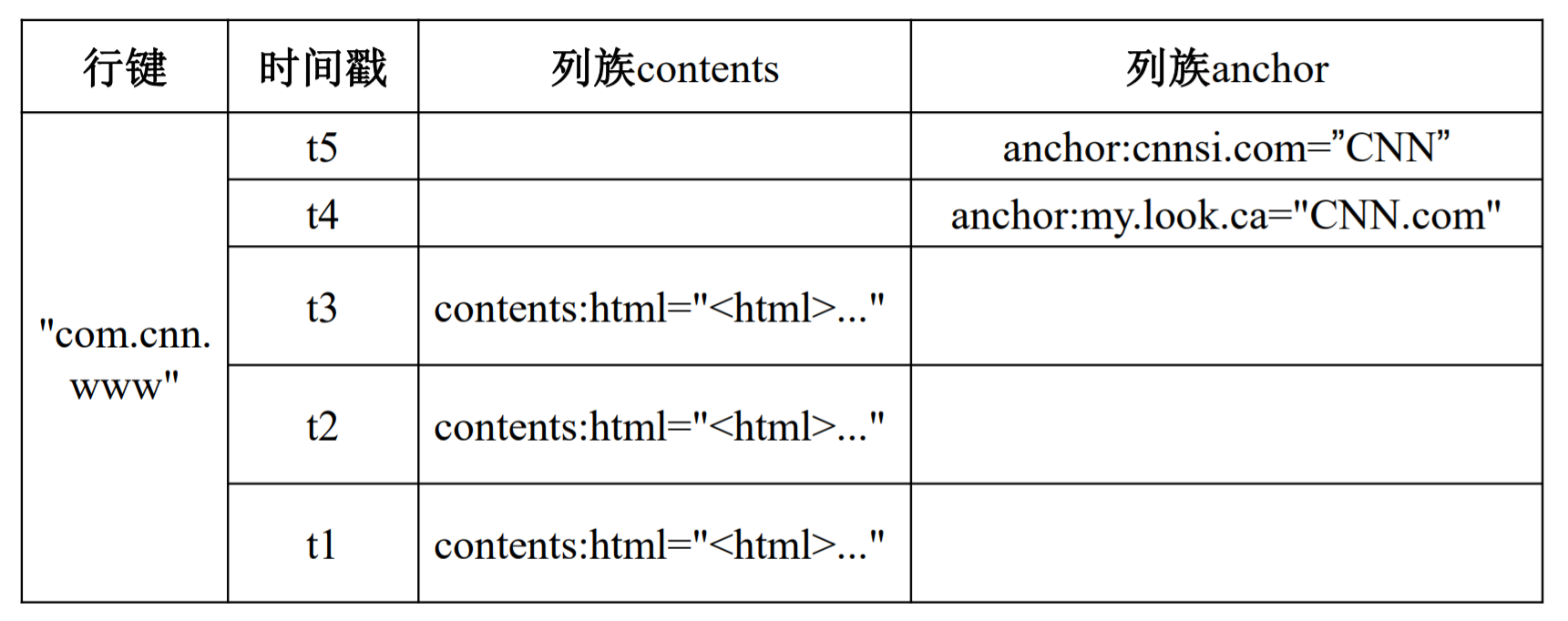
物理视图
同一列族的数据保存在一起
面向列的存储
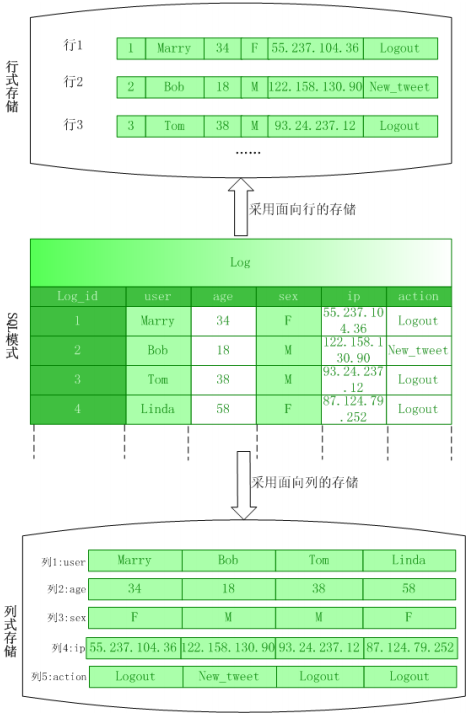
- 列式数据库采用DSM(decomposition storage model)存储模型
HBase的实现原理
HBase功能组件
3个主要的功能组件:
- 库函数:链接到每个客户端,客户端能利用库函数访问HBase数据库
- 一个Master主服务器:管家作用
- 负责管理和维护HBase表的分区信息
- 维护Region服务器列表
- 分配Region
- 负载平衡
- 处理模式变化(表和列族的创建等)
- 许多个Region服务器:负责存储和维护分配给自己的Region,处理来自客户端的读写请求
- 客户端并不是直接从Master主服务器上读取数据,而是在获得Region的存储位置信息后,直接从Region服务器上读取数据。
- 客户端并不依赖Master,而是通过Zookeeper来获得Region位置信息,大多数客户端甚至从来不和Master通信,这种设计方式使得Master负载很小
表和Region
根据行键的值对表中的行进行分区,每个行区间构成一个分区(Region):
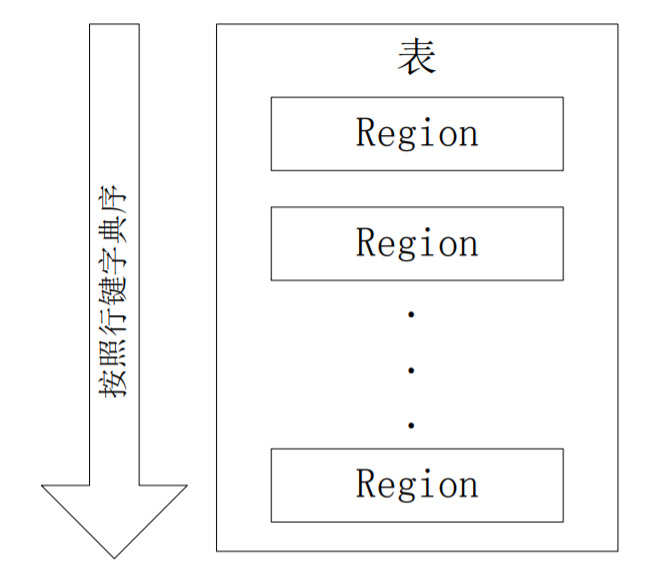
- 开始只有一个Region,当Region中的行数达到一个阈值时开始分裂成两个表,随后不断分裂,一个Region会分裂成多个新的Region:
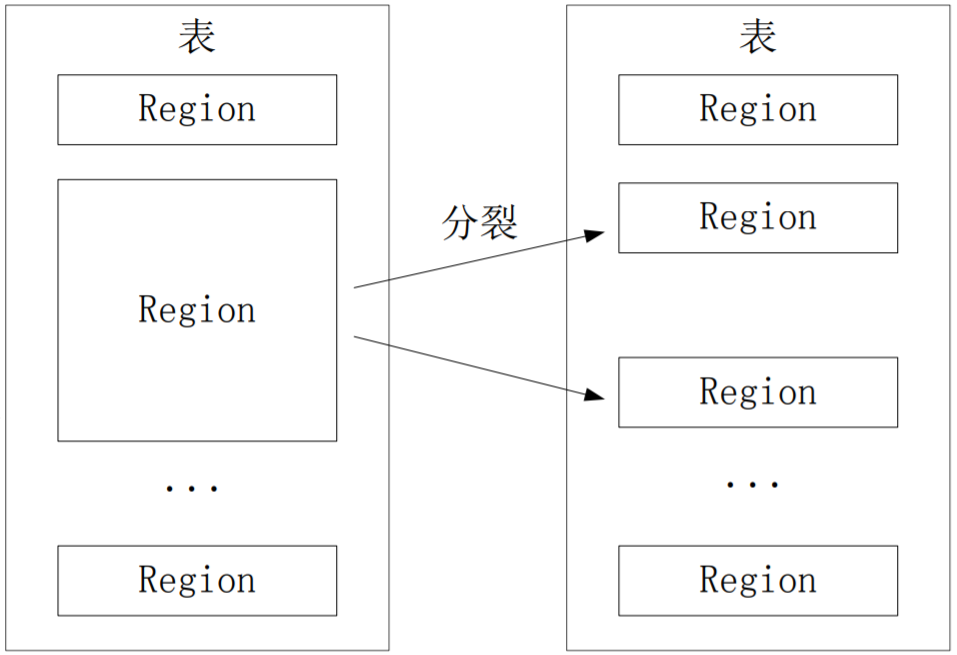
- Region拆分操作非常快,接近瞬间,因为拆分之后的Region读取的仍然是原存储文件(只是修改了指向信息),直到“合并”过程把存储文件异步地写到独立的文件之后,才会读取新文件
- 目前每个Region最佳大小建议1GB-2GB(实际大小取决于单台服务器的有效处理能力)
- Master主服务器会把不同的Region分配到不同的Region服务器上,但拆分过程中同一个Region不会被拆到多个Region服务器
- 每个Region服务器管理一个Region集合,大概存储10-1000个Region
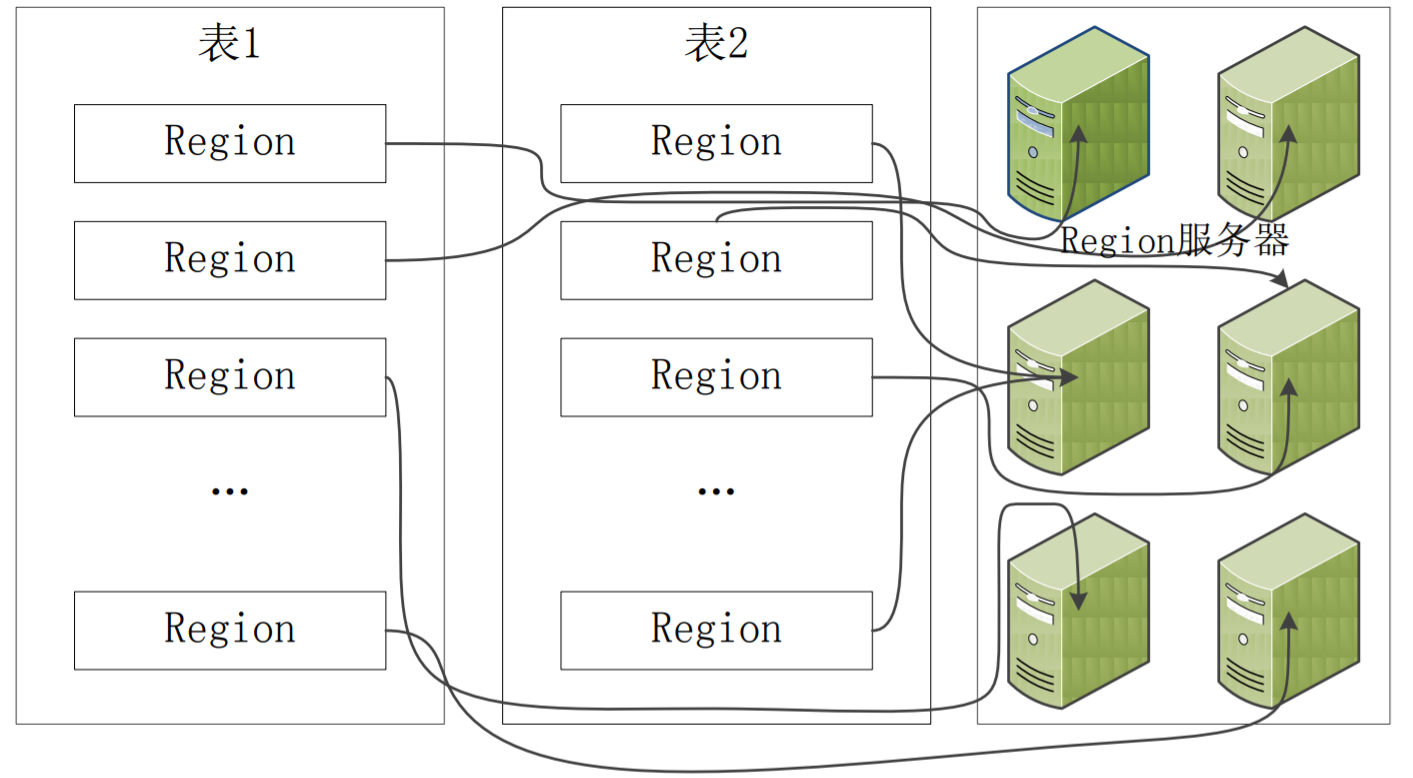
Region的定位
元数据表(.META.表):存储了Region(Region标识符,“表名+开始主键+RegionID”)和Region服务器的映射关系。当HBase表很大时, .META.表也会被分裂成多个Region。
根数据表(-ROOT-表):记录所有元数据的具体位置(.META.表的分裂信息),只有唯一一个Region(不可分割),名字是在程序中被写死的
Zookeeper文件:记录了-ROOT-表的位置
HBase的三层结构(三级寻址过程)(类似B+树):
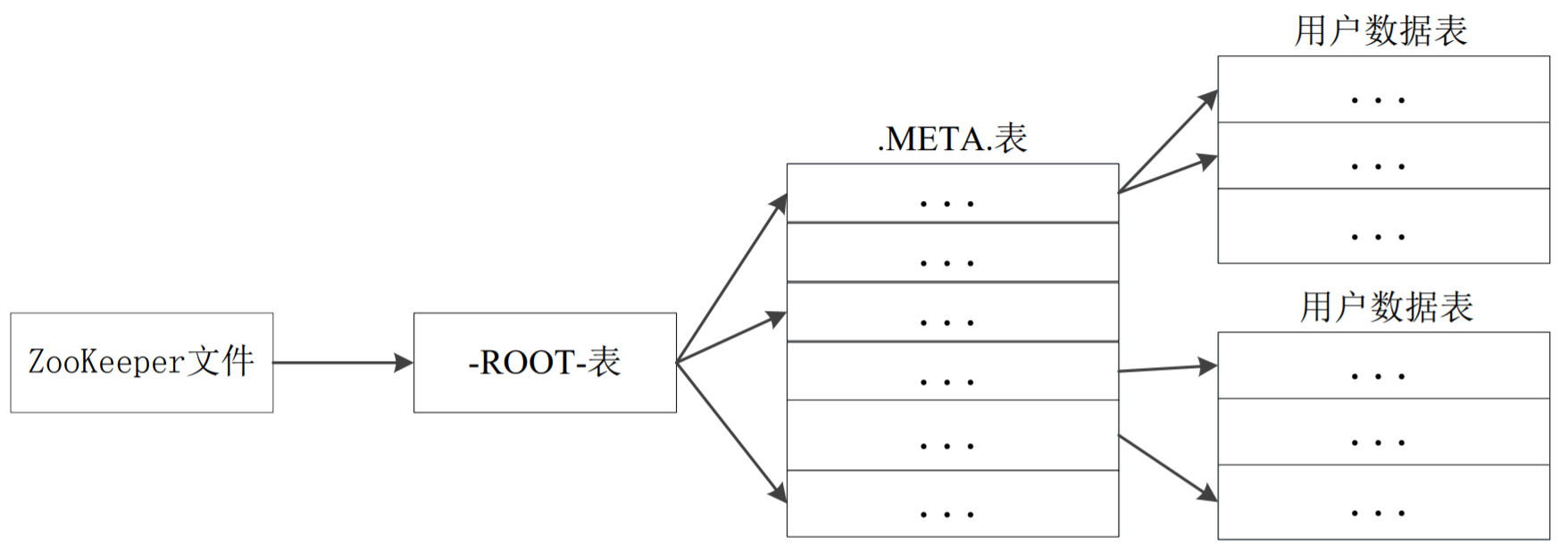
.META.表的全部Region都会被保存在内存中,三层结构可以保存的用户数据表的Region数目的计算方法是:
(-ROOT-表能够寻址的.META.表的Region个数)×(每个.META.表的Region可以寻址的用户数据表的Region个数)
其中每个表中的Region个数=每个Region的限制容量/每行(一个映射条目)在内存中占用的大小
客户端访问数据时的“三级寻址”:
- 为了加速寻址,客户端会缓存位置信息,同时,需要解决缓存失效问题(惰性解决机制,仅在使用该缓存没找到对应数据后才判定缓存失效)
- 寻址过程客户端只需要询问Zookeeper服务器,不需要连接Master服务器
HBase运行机制
HBase系统架构
系统架构图:
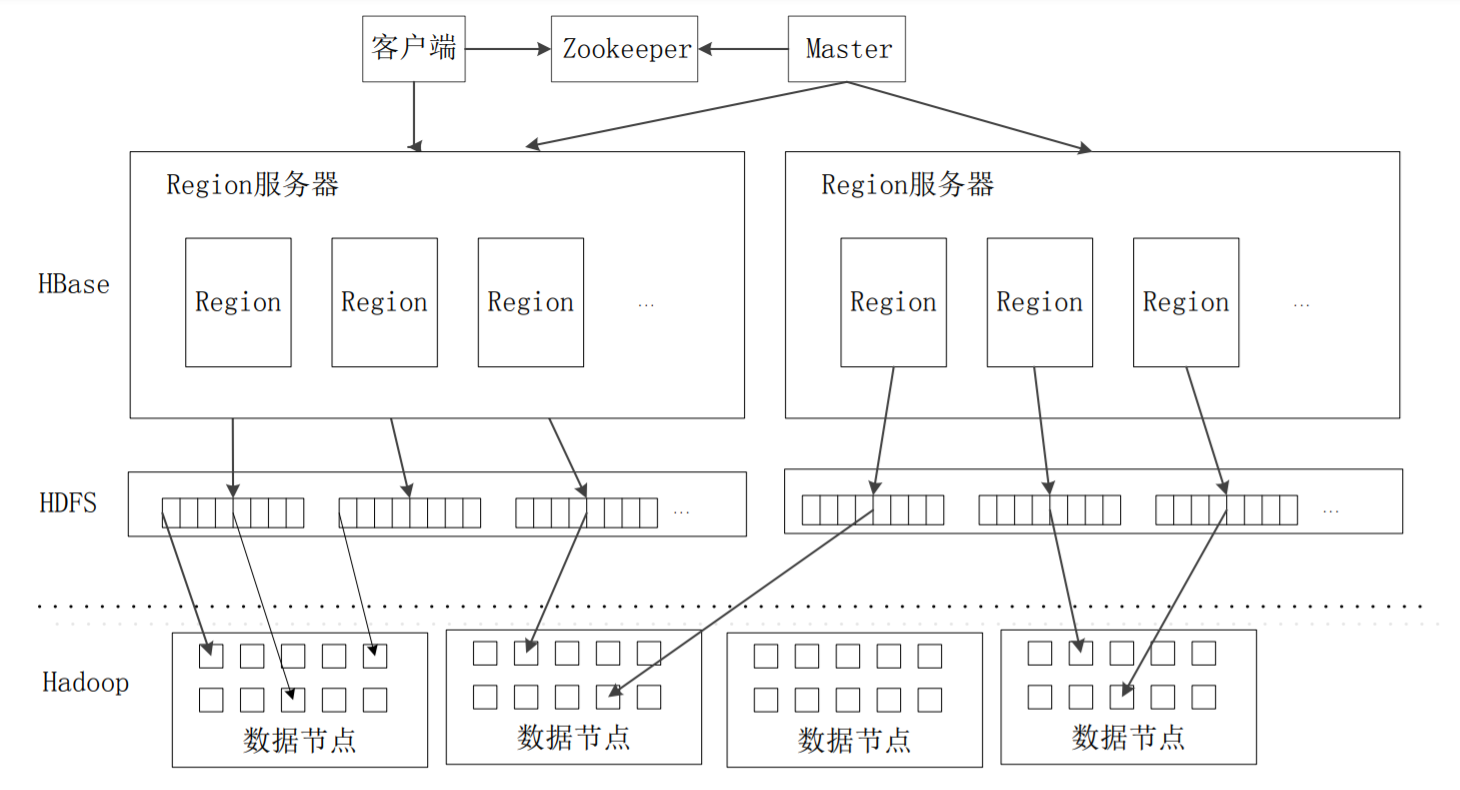
HBase采用HDFS作为底层存储,自身不具备数据复制和维护数据副本的功能,而HDFS提供这些支持。
客户端
- 访问HBase的接口
- 在缓存中维护着已经访问过的Region位置信息,用来加快后续数据访问过程
- 使用RPC机制与Master和Region服务器通信
Zookeeper服务器
每个Region服务器都到Zookeeper中注册,Zookeeper实时监控每个Region服务器的状态并通知给Master
帮助选举出一个Master作为集群的总管,并保证在任何时刻总有唯一一个Master在运行,避免了Master的“单点失效”问题
保存-ROOT-表和Master的地址,以供客户端访问获得
Zookeeper是一个很好的集群管理工具,被大量用于分布式计算,提供配置维护、域名服务、分布式同步、组服务等。
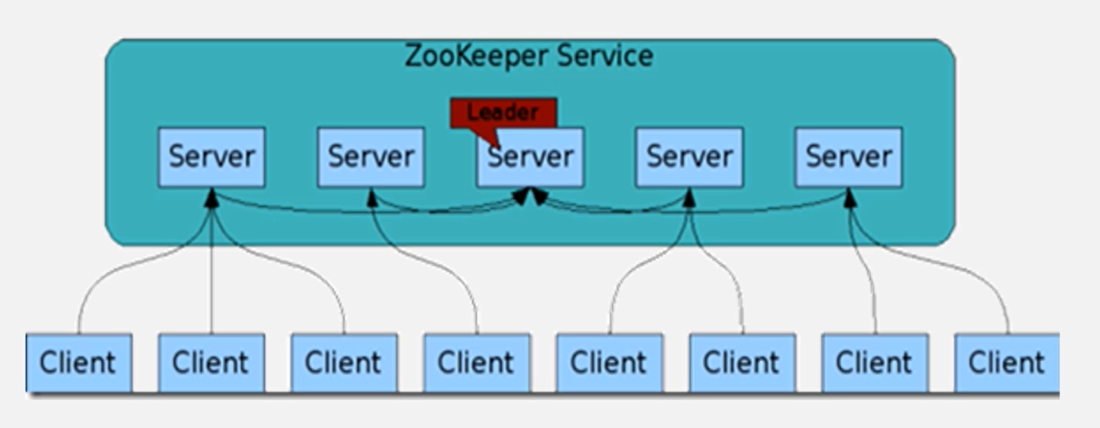
Master
- 管理用户对表的增加、删除、修改、查询等操作
- 实现不同Region服务器之间的负载均衡
- 在Region分裂或合并后,负责重新调整Region的分布
- 对发生故障失效的Region服务器上的Region进行迁移
Region服务器
HBase中最核心的模块,负责维护分配给自己的Region,并响应用户的读写请求
Region服务器工作原理
Region服务器体系:
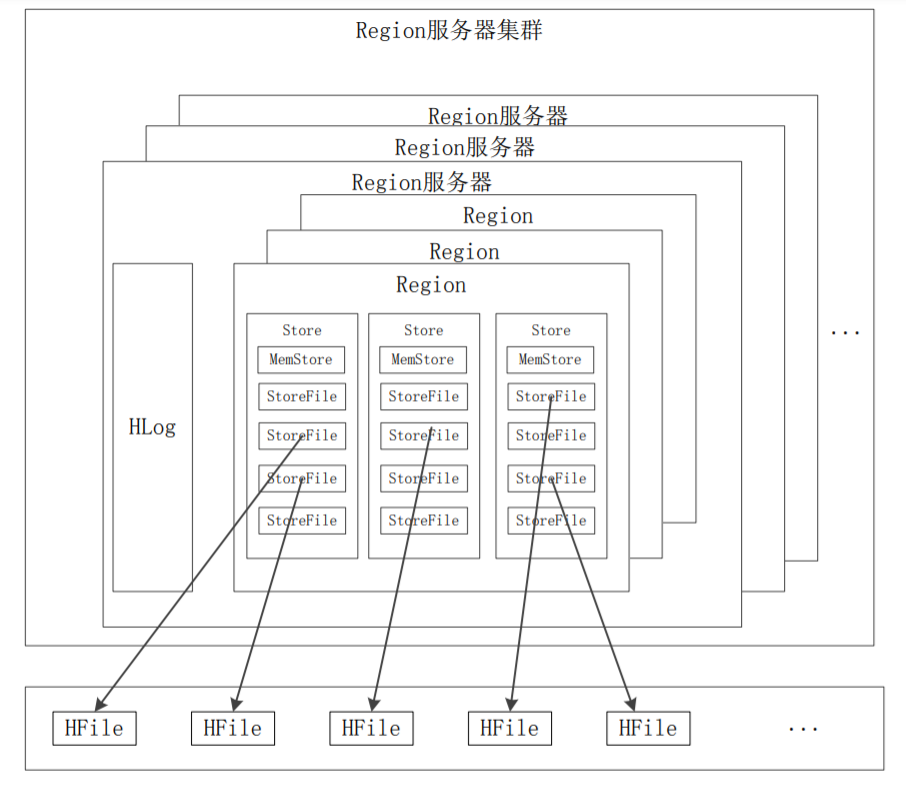
- 每一台Region服务器可以存储10-1000个Region
- 所有Region共用一个日志文件HLog
- 在存储中每个Region的每个列族会单独构成一个Store
- 每个Store包含一个MemStore和若干个StoreFile
- MemStore:在内存中的缓存,保存最近更新的数据
- StoreFile:磁盘文件,MemStore满了之后再刷写,实现方式是HDFS文件系统的HFile
用户读写数据过程
- 写入数据时,被分配到相应Region服务器去执行,首先被写入到MemStore和Hlog中,当操作写入Hlog之后,commit()调用才会将其返回给客户端
- 读取数据时,Region服务器会首先访问MemStore缓存,如果找不到,再去磁盘上面的StoreFile中寻找
缓存的刷新
- 周期性地把MemStore缓存里的内容刷写到磁盘的StoreFile文件中,清空缓存,并在Hlog里面写入一个标记表示已写入。每次刷写都生成一个新的StoreFile文件。
- Region服务器每次启动都检查HLog,确认最近一次执行缓存刷新操作之后是否发生新的写入操作:若发现更新,则先写入MemStore,再刷新缓存并删除旧的HLog文件,才开始提供服务。
StoreFile的合并
当StoreFile文件数量达到一个阈值后,调用Store.compact()把多个合并成一个,减少查找时间方便访问某个Store中的某个值。
Store工作原理
Store是Region服务器的核心
StoreFile的合并与分裂(Region分裂发生的地方):
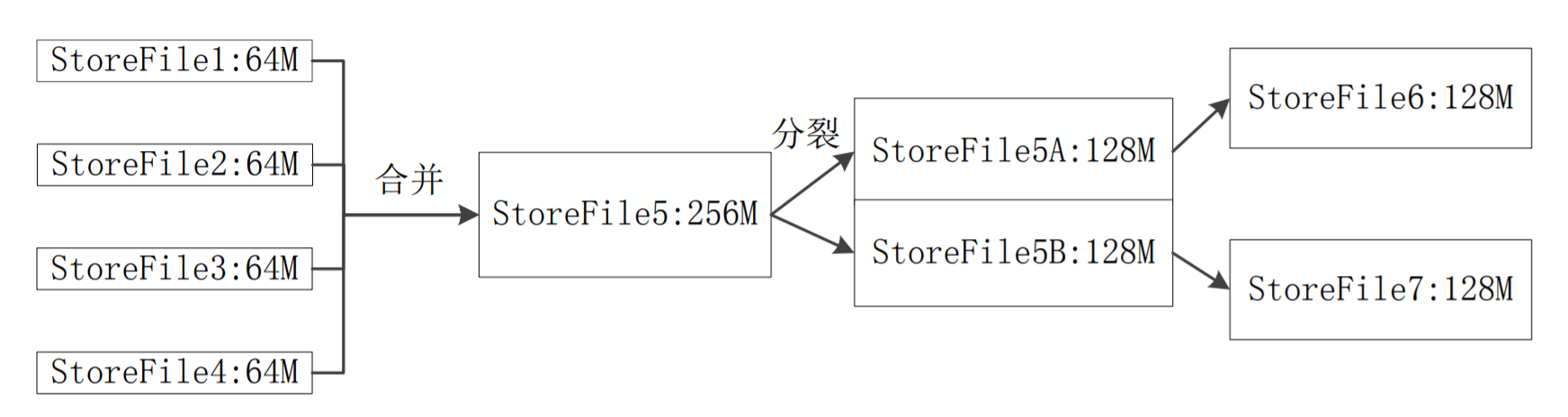
- StoreFile文件数量达到阈值时触发合并操作
- 单个StoreFile文件大小达到阈值时触发分裂操作
HLog工作原理
分布式环境必须要考虑系统出错后能够回恢复。
HLog文件:预写式日志(Write Ahead Log)
用户更新数据的步骤:
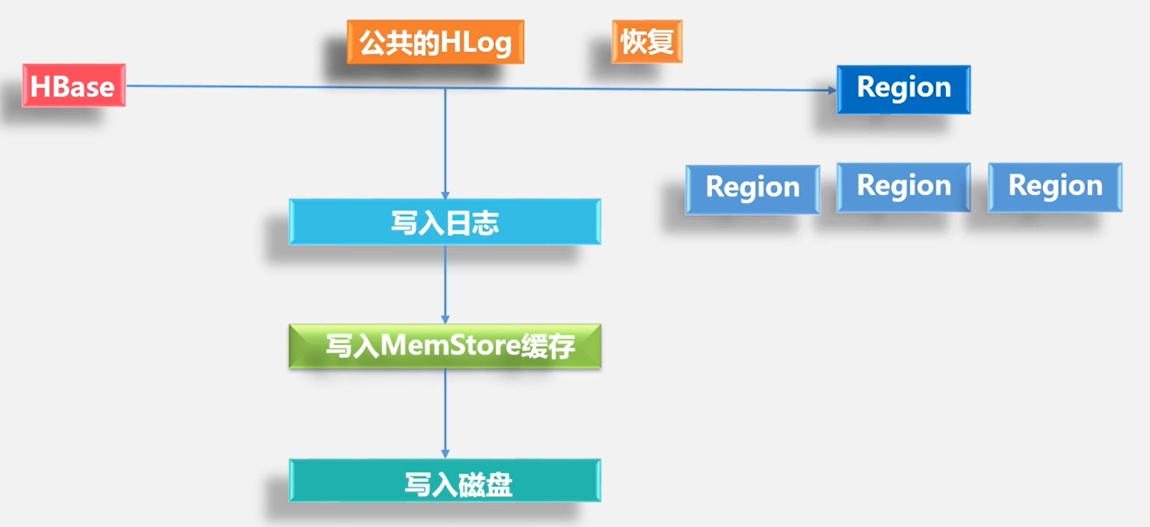
Zookeeper实时监测每个Region服务器的状态,当某个Region服务器发生故障时:
- Zookeeper通知Master
- Master首先会处理该故障Region服务器上面遗留的HLog文件:包含了来自多个Region对象的日志记录,对HLog数据进行拆分,分别放到相应Region对象的目录下
- 将失效的Region重新分配到可用的Region服务器中,并把与该Region对象相关的HLog日志记录也发送给相应的Region服务器
- Region服务器领取到分配给自己的Region对象以及与之相关的HLog日志记录以后,重做一遍日志记录中的各种操作
一个Region服务器中各个Region共用一个HLog日志:
- 优点:减少磁盘寻址字数,提高对表的写操作性能
- 缺点:恢复时需要分拆日志
HBase应用方案
HBase实际应用中的性能优化方法
把常用数据保存到一起
行键是按照字典序存储,因此,设计行键时,要充分利用这个排序特点,将经常一起读取的数据存储到一块,将最近可能会被访问的数据放在一块:
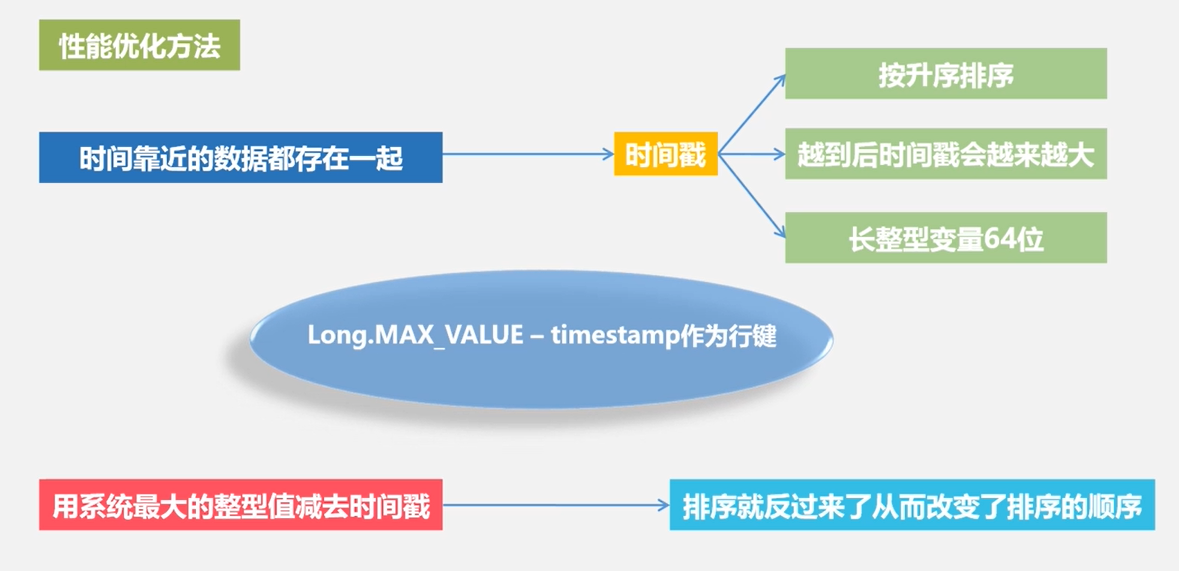
提升读写性能
InMemory:设置HColumnDescriptor.setInMemory(true)将表放到Region服务器的缓存中,保证在读取的时候被cache命中
Max Version:将HColumnDescriptor.setMaxVersions(int maxVersions)设置表中数据的最大版本,节省存储空间
InMemory:将HColumnDescriptor.setTimeToLive(int timeToLive)设置表中数据的存储生命期,过期数据将自动被删除
在HBase之上构建SQL引擎
在NoSQL数据存储HBase上提供SQL接口的原因:
- 易使用
- 减少编码
方案:
- Hive整合HBase
- Phoenix
构建HBase二级索引
原生HBase产品不支持对各个列构建相关索引,只能:
- 通过单个行键访问
- 通过一个行键的区间来访问
- 全表扫描
采用HBase0.92版本之后引入的Coprocessor特性,可以构建二级索引:
- Coprocessor提供了两个实现:endpoint和observer,endpoint相当于关系型数据库的存储过程,而observer则相当于触发器
- observer允许我们在记录put前后做一些处理,因此,而我们可以在插入数据时同步写入索引表,生成相对于主表的另一个表
为HBase行健提供索引功能的产品:
- Hindex二级索引
- HBase+Redis
- HBase+solr
HBase性能监视
- Master-status(自带)
- Ganglia
- OpenTSDB
- Ambari
HBase编程实践
详细安装过程参考: