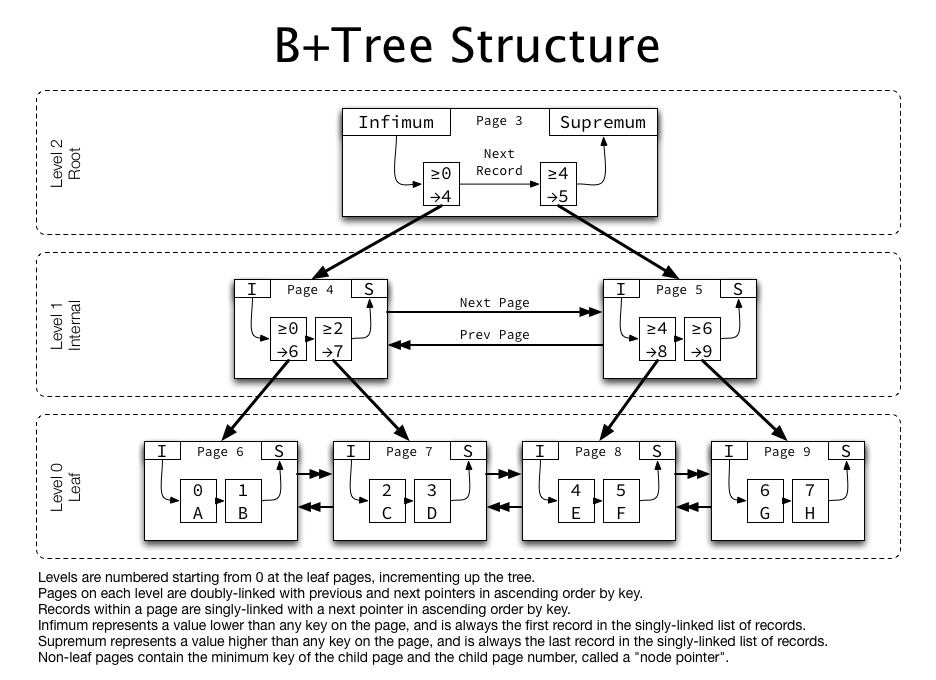
Hadoop3.1.3安装教程:单机&伪分布式配置
Intro当开始着手实践 Hadoop 时,安装 Hadoop 就是第一步。感谢林子雨教授实验室提供的Hadoop系列完整教程,让我不再纠结各种博客里的差错。本文相当于转发一下系列教程中的Hadoop3.1.3安装教程_单机/伪分布式配置_Hadoop3.1.3/Ubuntu18.04(16.04),再附上一点本人安装过程中的记录,以备参考。
环境原教程使用 Ubuntu 18.04 64位 作为系统环境,本人使用 Ubuntu 20.04 64位,两个环境在操作过程中无差异。
创建hadoop用户如果安装 Ubuntu 的时候不是用的 “hadoop” 用户(一般肯定不是),那么需要增加一个名为 hadoop 的用户,在终端输入:
1sudo useradd -m hadoop -s /bin/bash
这条命令创建了可以登陆的 hadoop 用户,并使用 /bin/bash 作为 shell。
接着使用如下命令设置密码,按提示输入两次密码:
1sudo passwd hadoop
可为 hadoop 用户增加管理员权限,方便部署,避免一些比较棘手的权限问题:
1sudo addus ...
Java学习笔记(一)——杂七杂八的tips
Intro前几天突然接到一个用Java复现Python代码的活,把我这个Java零基础的人折磨得要命。借此契机入门Java的同时也先记一下某一些特定的tips,方便以后查阅吧。
四舍五入12int start = (int)Math.round(Float.parseFloat(start_video_locations.get(index2).toString()))//start_video_locations为Object类型的变量
List的去重1List course_ids = (List) course_ids_col.stream().distinct().collect(Collectors.toList());
List的排序1Collections.sort(list_name);
获取list长度1int list_length = list.size();
object类型的小数转成double12double score = Double.valueOf(String.valueOf(ques_df.row(0).get(3)));//这里q ...

在终端以命令行形式编译带第三方jar包的Java程序
eclipse爬
背景:在一个.java文件里import了一个第三方包,然后从网上下载了它的.jar文件。不管.java文件和.jar文件放在什么地方,以下命令皆适用:
12javac -cp package_name.jar class_name.javajava -cp .:package_name.jar class_name
注:
-cp和-classpath是一样的功能,-cp是简写。
若两个文件不在同一个地方,记得视终端所在位置而定是否需要写上.jar或.java文件的绝对路径。
java命令中的.代表当前路径(这里假设终端在.java文件处打开),而冒号:(假设为Linux系统,Windows系统改为分号;)表示多个路径之间的间隔,在引用多个.jar包和.jar包与主程序生成的.class时必须用到。
参考文章:java -cp -classpath 引用多个jar的方法
用apt方式在Ubuntu中直接安装Sublime Text
由于apt与Ubuntu的绝配,Sublime Text官方提供了一种懒人专用的安装方法:官方文档,apt-get之后就不用再去设置什么路径。其余Linux版本也可以参考文档里后面的内容。
注意:去过 https://download.sublimetext.com/ 这个网址下载过安装包的应该都知道下载速度奇慢无比,建议在科学上网环境下进行以下操作,最后apt下载的是一个大概9M大小的归档。
安装步骤:
123456789101112131415# 安装GPG密钥:wget -qO - https://download.sublimetext.com/sublimehq-pub.gpg | sudo apt-key add -# 确保apt设置为使用https源sudo apt-get install apt-transport-https# 选择要使用的版本(以下两个二选一)# 稳定版echo "deb https://download.sublimetext.com/ apt/stable/" | sudo tee /etc/apt/sources.list. ...

大数据技术综述
1 大数据概述1.1 定义巨量数据集合,指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。
1.2 特征(4V)
Volume:数据的超大规模
Variety:数据来源多样性与异构性
Velocity:数据的高处理速度
Value:数据价值密度低
1.3 大数据思维
要相关,不要因果。大数据时代认为没有必要非得知道现象背后的原因,而是要让数据自己“发声”。
要全体,不要抽样。大数据时代认为要分析与某事物相关的所有数据,而非少量的数据样本。
要效率,允许不精确,要注重效率,而不再追求精确。
2 大数据技术体系
图片来源
2.1 数据来源
参考文章1参考文章2
2.1.1 结构化数据结构化的数据是指可以使用关系型数据库表示和存储,表现为二维形式的数据。一般特点是:数据以行为单位,一行数据表示一个实体的信息,每一行数据的属性是相同的。
结构化数据的存储和排列很有规律,便于查询和修改等操作,但扩展性不高。
2.1.2 半结构化数据半结构化数据是结构化数据的一种形式,它并 ...
Pyclustering模块中K-Medoids算法和Elbow(肘部)法则的应用
Introduction最近在做数据分析相关研究时需要用到K-Medoids算法对数据进行聚类,然后在平时常用的Python的sklearn.cluster库模块中没有找到这个算法函数,于是想着找一下别的库。首先是发现了一位研究数据分析的博主的一份笔记:K-medoids聚类算法原理简介&Python与R的实现,在文末评论里他提到博文中用的pyclust模块不维护了,然后推荐了pyclustering模块和其参考文档。为加深自己的理解,特此对文档做一份学习笔记。
K-Medoids文档渣翻与应用pyclustering.cluster.kmedoids.kmedoids:一个用于表征K-Medoids算法的类
公共类成员函数1234567891011121314151617def __init__ (self, data, initial_index_medoids, tolerance=0.001, ccore=True, kwargs)# K-Medoids聚类算法的构造初始化def process (self)# 根据K-Medoids算法的规则进行聚类分析def pre ...

从Ubuntu19.10直接升级到20.04LTS
2020年4月23日,代号为“Focal Fossa”的Ubuntu 20.04 LTS的最终稳定版本发布。作为第八个LTS版本,Ubuntu 20.04 LTS将在之后一段时间内作为最大的版本存在 ,其重大更新和改进将在2030年前终止,而Ubuntu 19.10生命周期将在今年7月结束。
有一说一,作为一个用了半年19.10的人,我个人感觉20.04变化不大——但19毕竟比较短命所以还是升级到LTS比较好。问题是这半年里我在19.10中配了一大堆环境。因此,每次一想不开就重装系统熟练得都可以开店了的我第一次尝试了在系统中直接升级,特此记录一下操作的步骤。
注意:任何升级操作之前请备份好原系统中的重要文件!
P.S.系统直接升级到20.04仅适用于Ubuntu 18.04 LTS和Ubuntu 19.10,其他版本请先升级为这两个版本之后再进行升级。以下演示步骤的系统环境为19.10版本,18.04中的界面稍有区别但过程基本相同。
首先,一步到位的方式就是开机之后系统刚好给你弹出一个这个窗口,无脑点升级即可搞定:
但在系统不自动检测新版本的情况下,需要我们自己手动操作几步:
首先在 ...

用Python连接Hive所需库的安装步骤
在Python中,类比于pymysql包连接MySQL数据库,可以利用impala包的impala.dbapi连接Hive数据库,建立起来的连接和游标cursor.execute(sql)之后,后续查询操作基本上与pymysql相似。所需要的库的安装过程如下:
参考:
python 安装impala包
python安装thrift-sasl提示缺少sasl.h文件
安装环境:Ubuntu20.04 LTS
按以下步骤来安装即可:
123456pip install sixpip install bit_arraypip install thriftpyapt-get install python-dev libsasl2-dev gccpip install thrift_saslpip install impyla
其中apt-get install python-dev libsasl2-dev gcc是为了解决在pip install thrift_sasl中需要编译而缺少相应软件产生的如下报错(Windows系统可参考这里):
12345678910111213141516 ...

你听,江水流过人家吵着要上岸【多图预警】
仙湖边有船微光照彼岸我是这船上客它陪我渡孤单
Intro2020年5月16日的早上,刚醒来的我像过去两天里拿起手机的第一反应一样登上学院的官网,不同的是,这一次刷出了成绩的公示。看到自己名字后面备注中的“计划内待录取”,又睡了回去……
过去的一年里,为了不毒奶自己,我无数次忍住了在各种社交网站上发一些与考研相关的动态的欲望,很多张记录了某个时刻的照片和截图只静静躺在自己手机的相册里,心想着要一直低调到录取的那一天。现在这一天来了,不写点什么好像不太对得起过去这接近一年的时光和记忆。不想被乌烟瘴气的微博污染,又不想折腾一个微信公众号还要重操旧业搞排版,于是想起了由于严重的拖延症在本科搁置了差不多三年的想要搭个博客的计划,干脆就把这些活一并干完了。
这篇文章可以说是一个过去一年里我缺失的朋友圈的合集,也整合了一些曾经忍不住发了出来的动态,就以这种图文的形式把2019年6月后至今的这段时间串联起来,方便日后自己的回顾。
热夏考研的故事通常从一年的春天开始,但是这里第一个标题是热夏,就是因为我懒。
大三的下学期一开学,我的书架上就专门腾出了一个格子放了这些书:
张宇数二的27讲+1000 ...

Hello Blog
“Hello World”
致谢:
Lfalive和薄论的推荐
来自Jerryc的Butterfly主题
参考教程:
Butterfly文档
Hexo+github搭建博客教程
Markdown教程
希望在这个博客里记录未来更真实的生活。
注:本博客封面头图via微博@千葉幽羽bili,个人头像via微博@卷卷的自然卷0,本文章插图及网页图标viaLOFTER@pumapuma,均非商业用途,侵删。
2021.9.11 update:
网页图标更新为推特用户@Scott_McRoy的这张: